
在处理 Java 应用的线上问题时,常会遇到系统运行缓慢、或页面出现延迟卡顿的现象,如果不是网络原因,那我们该如何对这类问题进行分析定位呢?下面就介绍一些会造成系统卡顿的原因,以及对应的排查方法。
正式介绍前想提一句,无论最终查出是什么问题,大概率是我们自己写出来的,JDK 发展了这么多年,由 JDK 本身引起的问题少之又少。所以,在平时的开发中,我们要尽量符合开发规范,多审查自己的代码,应极力避免上线后再去解决问题。如常见的定时任务、循环代码写得不严谨,导致某个操作不停地执行,最终耗尽资源,这类问题是完全可以避免的。
另外,在排查问题之前,如果出现的问题导致线上系统不可用,那么首先要做的,是导出我们需要的系统信息,比如堆转储文件,然后重启系统,尽快保证系统的可用性。
排查问题的思路很简单,那就是搜集尽可能多的日志,然后根据这些报错信息,缩小问题代码范围,找到具体是哪几行代码写得不妥,再做针对性的优化即可。
1 CPU 飙高
造成 CPU 飙高的原因主要有两种:
(1)内存溢出,导致频繁 Full GC,而每次 Full GC 的停顿时间都较长,所以系统出现卡顿。
(2)代码中有比较耗 CPU 的操作,比如死循环,一直占用 CPU,导致 CPU 过高,系统变慢。
两种情况都可以通过下文中介绍的两种排查思路去解决。两者的区别在于,如果是因为内存溢出导致,那么通过 jstack(下文中有介绍)得到的线程栈信息中会包含大量的 VM Thread(代表垃圾回收线程);而如果是因为耗 CPU 的代码导致,那么得到的就是一个业务线程的具体堆栈信息,包含用户自定义的类,可以从中直接找到问题代码的行数。
解决 CPU 飙高这个问题大致有两个思路:
1.1 第一个思路
(1)先找到占用 CPU 高的进程;
(2)再找到占用 CPU 高的线程;
(3)最后找到占用 CPU 高的线程对应的业务代码。
(1)先找到占用 CPU 高的进程
执行「top」或「top -c」命令,显示进程运行信息列表,再键入大写 P,列表会按 CPU 使用率降序排列:
1 | top |
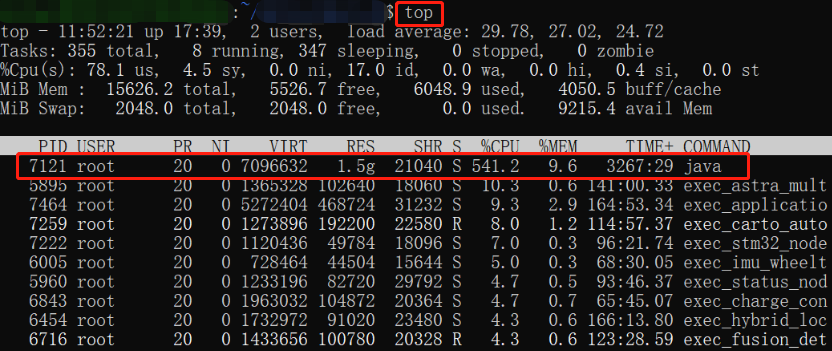
这里要注意的是,如果 Java 程序部署在 Docker 中,那么需要先进入运行 Java 程序的 Docker 容器,然后在容器里执行「top」命令:
1 | sudo docker exec -it [containerId] bash |
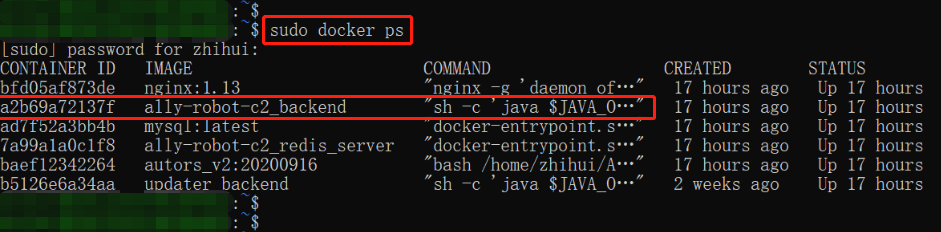
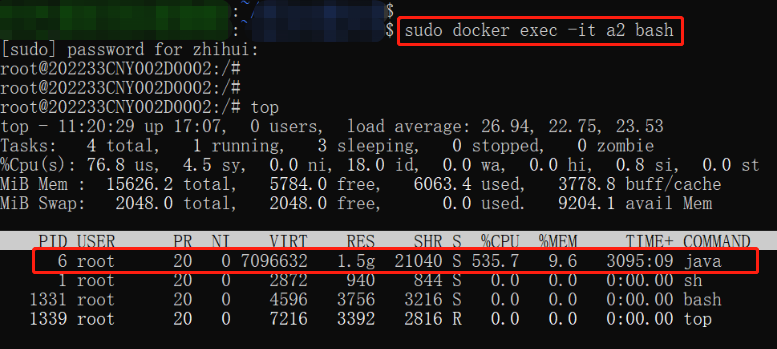
如图所示,占用 CPU 资源最高的达到了 535.7%,记住它的进程 PID,为 6,后续命令中会用到。
(2)再找到占用 CPU 高的线程
一个进程内有多个线程,执行「top -Hp 6」,显示进程 PID 为 6 的线程列表,键入大写的 P 后,列表会按 CPU 使用率降序排列:
1 | top -Hp 6 |
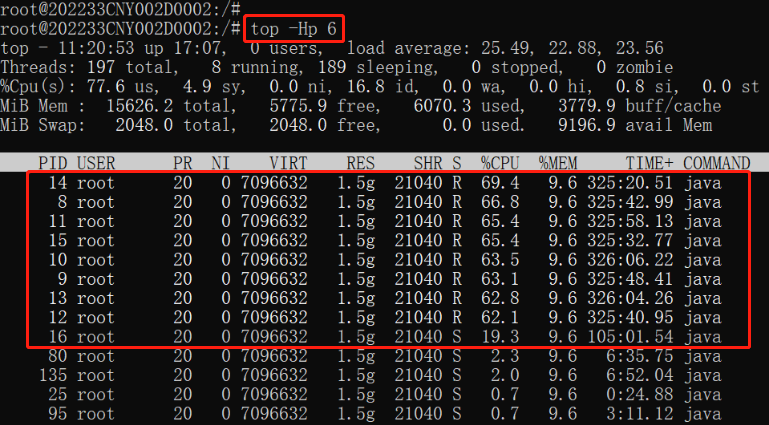
我们发现在列表中有多个占用 CPU 资源比较高的线程,其实大部分都是 GC 线程,选择其中一个即可,比如选线程 PID 为 14 的线程,CPU 使用率为 69.4%。
(3)最后找到占用 CPU 高的线程对应的业务代码
这里要进行一个转换,将线程的 PID(14)转为十六进制,因为在 jstack 打印出的线程栈信息中,线程的 PID 是用十六进制显示的。转换方法:
1 | printf "%x\n" 14 |
获取到 14 的十六进制表示为 e。最后通过 jstack 检索进程(进程 PID = 6)中最耗 CPU 资源的线程(线程 PID = e)的线程栈信息,执行 jstack 命令:
1 | jstack 6 | grep "0xe" -C5 --color |
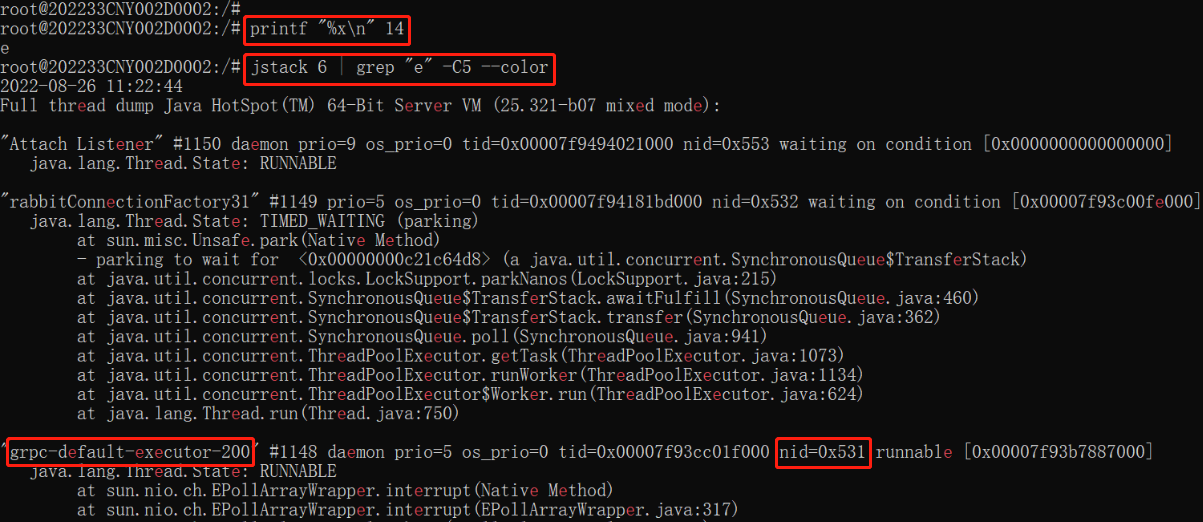
通过在线程栈信息中高亮显示的 0xe,我们可以快速找到对应的线程名称。比如在上图中,如果线程的十六进制 PID 是 531,那我们就可以找到线程 nid=0x531 对应的线程名称为 grpc-default-executor-200,这个线程名称是我们在业务代码中给线程取的名称。因此,给线程取一个与业务处理相关的名称,对快速定位问题尤为重要。如果只通过 jdk 生成的线程名称,以及只包含 jdk 代码的线程栈信息,是无法定位到业务代码的。
如果发现信息中包含文本「Full GC (System.gc())」,说明代码或第三方依赖包中有显式的 System.gc() 调用。
1.2 第二个思路
(1)生成堆转储文件(也就是生成 heap dump,它是一个二进制文件,保存了某一时刻 JVM 堆内存中的对象使用情况;与之相似的还有 thread dump,用于记录 CPU 信息);
(2)分析堆转储文件。
(1)生成堆转储文件
生成堆内存转储文件主要用到命令 jmap, jmap 命令是 JDK 提供的用于查看或生成堆内存信息的工具。生成命令:
1 | 生成命令: jmap -dump:live,format=b,file=heap.hprof <pid> |
live:仅打印具有活动引用的对象,丢弃那些准备垃圾回收的对象,可选参数;
format=b:以二进制格式转储;
file:转储文件路径,文件后缀通常为 hprof 或 bin;
pid:进程 id。
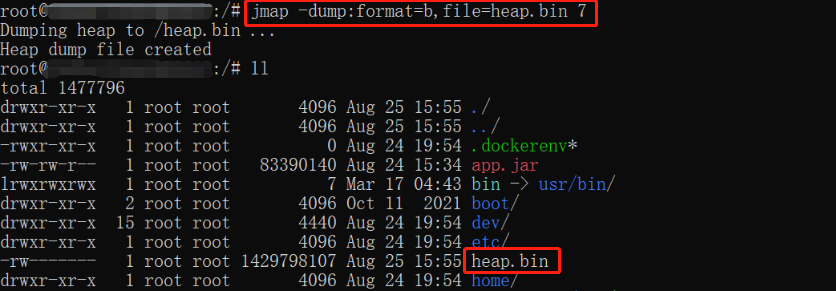
使用 jmap 命令有一点不好的地方是,内存溢出是某个时间点发生的事情,跟执行 jmap 命令的时候获取到的转储文件相比,存在时间差问题。所以这里再介绍一个 Java 虚拟机参数:
1 | -XX:+HeapDumpOnOutOfMemoryError |
设置了这个 Java 虚拟机参数之后,它就会在程序发生内存溢出的时候,自动生成一个二进制的堆转储文件,这个转储文件的后缀为 hprof,而且这个文件几乎是在发生内存溢出的同时生成的,故而会更准确些。这个文件的存储路径也可以通过参数指定:(如果不指定,则默认在当前工作目录下生成 java_pid
1 | 指定相对路径、绝对路径都可以,但要注意,就是必须确保文件路径事先已创建好,如果路径不存在,它不会自动创建 |
建议提前添加 -XX:+HeapDumpOnOutOfMemoryError 参数,而不是用 jmap。有几点要注意,内存分析可能需要比对多个堆转储文件,除了在发生内存溢出时自动生成的堆转储文件外,我们在获取其他时间点的堆转储文件时一定要找准时机,避免得到一个没用的快照。另外,每次执行堆转储,都会对 JVM 进行「冻结」,所以在生产环境中不能执行太多次的 dump 操作,一旦系统缓慢或者卡死,麻烦就大了。(快照中也可能含有机密信息,例如密码等,这时候如果企业有安全限制,还需先获得在生产服务器上执行堆转储的权限)
(2)分析堆转储文件
分析堆内存转储文件主要用到命令 jhat,jhat 命令也是 JDK 自带的用于分析 heap dump 文件的工具。使用下面的命令可以将堆转储文件的分析结果以 HTML 网页的形式进行展示:(如果系统有可视化界面,也推荐用工具 MAT(Memory Analyzer Tools) 来分析,该工具既可以安装到 Eclipse 上使用,也可以独立运行使用,解压之后双击 MemoryAnalyzer.exe 即可)
1 | 分析命令:jhat <heap-dump-file> |
参数 -J-Xmx8192m 用来设置命令使用的内存大小,当然首先要保证执行命令的物理机器有足够大的内存,因为堆转储文件往往很大,不加这个参数的话有可能会报内存溢出异常,导致分析失败。如果加了此参数仍然不行,可以尝试设置下环境变量:
1 | JAVA_OPTS:-server -Xms4096m -Xmx4096m |
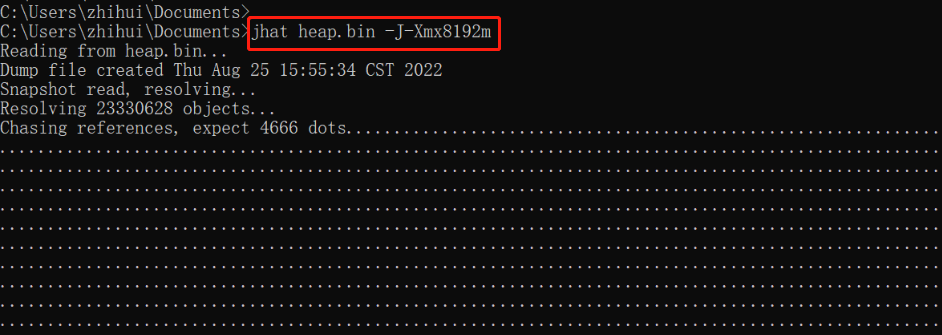
执行成功后显示如下结果:
1 | Snapshot resolved. |
这个时候访问 http://localhost:7000/ 就可以看到结果了:
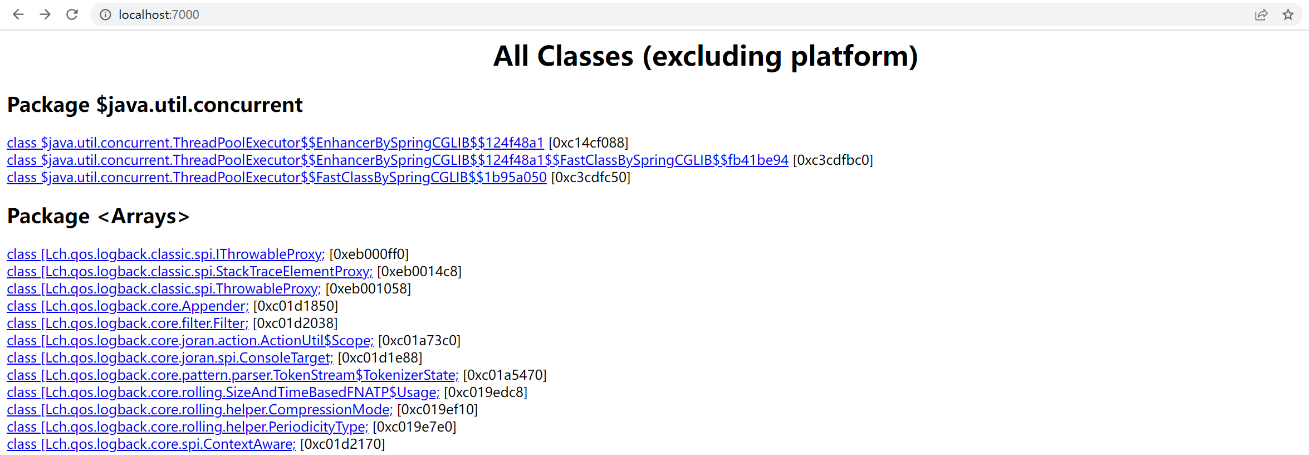
那如何从这个 HTML 网页中找到我们想要的有价值的信息呢?需要拉到网页最底部,找到 Other Queries,然后选择 Show instance counts for all classes (excluding platform),找除了 JDK 本身之外实例数最多的类:
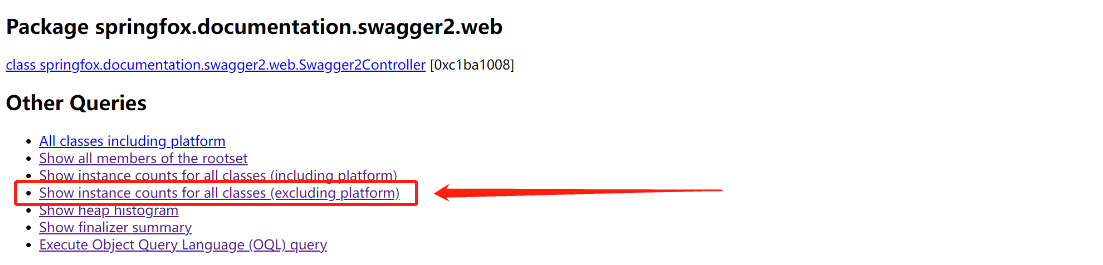
看看排名最前的几个类,就可以找出可能会分配大量对象的代码,基本就能定位到问题代码的位置了,如果对整个系统非常熟悉,找到的速度会更快:
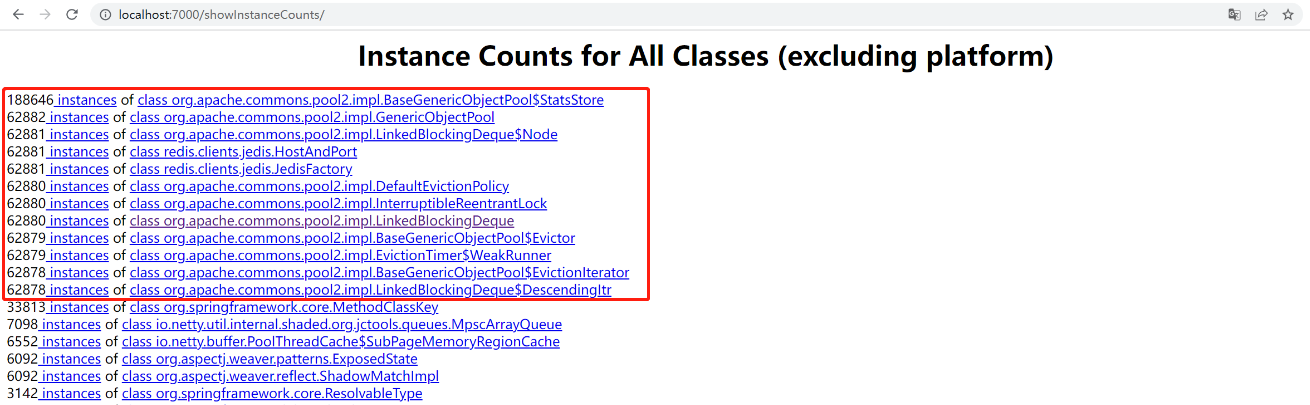
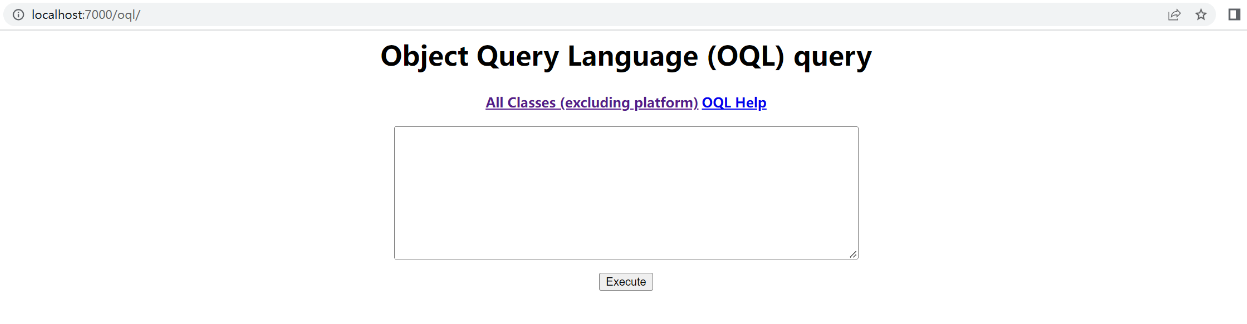
另外这里要提一下 OQL(Object Query Language),它的位置在 Other Queries 部分的最后一行,是 JDK 提供的一个查询 Java 堆信息的工具,它的语法跟 SQL 类似,用起来很方便,有需要的话可以学习一下(下图中的 OQL Help 有教学)。
2 内存溢出
2.1 排查思路
当 Java 应用消耗大量内存,导致出现异常:
1 | java.lang.OutOfMemoryError: GC overhead limit exceeded |
一般出于以下原因:
(1)JVM 内存过小;
(2)产生的垃圾过多,无法回收;
(3)代码有漏洞:
- 对象、线程创建太多,且一直未释放;
- 进行 IO 操作后不关闭流,资源无法释放;
- 消费者速度慢,生产者速度快,任务队列中对象不断堆积。
大多数情况下,通过配置 JVM 启动参数或增大堆内存并不能从根本上解决这个问题,只能延长错误发生的时间。要解决内存溢出问题需清楚两点:哪些对象占用了最多内存?这些对象是在哪部分代码中分配的?终极的解决办法是找到占用内存大的地方,优化相关代码。怎么找呢?依然是通过堆转储文件去找(生成和分析堆转储文件的方法在「CPU 飙高」部分介绍过,这里不再赘述)。
2.2 命令介绍
除直接分析堆转储文件外,还有一些值得学习的命令可以辅助我们排查问题,有时甚至只用这些命令就能定位到问题代码的位置。
(1)jmap -histo
如果想知道什么对象消耗内存最大,那么可以执行命令:
1 | 查看类的实例数量、占用的内存、类的名称:jmap -histo:live <pid> |
结果会以表格的方式显示存活对象的信息,并按对象所占的 bytes 大小进行降序排列(比如 18874368 bytes = 18M,若要包含未存活的对象,则删掉「:live」,更多用法,可通过「man jmap」寻求帮助)。如果发现某类对象占用内存很大,比如达到了几个 G,那大概率有问题。
(2)pstree
如果想知道创建了多少线程,可以执行命令:
1 | pstree -p <pid> | wc -l |
结果会显示进程内的线程数,还有每个线程的线程栈内存。
(3)jmap -heap
如果想查看堆(新生代、老年代)内存分配大小及使用情况,可以执行命令:
1 | 查看堆的使用情况:jmap -heap <pid> |
可用来确认是不是整体内存分配太小。
(4)jstat -gc
如果想查看实时的新生代、老年代内存使用情况及 GC 情况,可以执行命令:
1 | 提供 GC 和类装载活动的信息: jstat -gc <pid> |
其中,6 为进程ID,1000 为数据刷新间隔的毫秒数,更多的命令参数含义可通过「man jstat」寻求帮助。执行结果会显示各个区内存使用情况及 GC 的情况,结果列表表头含义:
- EC:Eden 区容量;
- EU:Eden 区已使用量;
- OC:Old 区容量;
- OU:Old 区已使用量;
- YGC:YongGC 次数(当新生代被填满时执行一次,回收速度快);
- YGCT:YongGC 耗时;
- FGC:FullGC 次数(当老年代被填满时执行一次,回收时应用程序会整个停下来直到回收完成);
- FGCT:FullGC 耗时。
3 产品功能运行缓慢
除了上文中一旦出现就很严重的两种情况外,还有三种情况,也会导致系统功能运行缓慢,但它的影响范围没那么大,出现问题后不会导致整个系统都不可用,最多只会让一个具体的功能变得很慢。跟上文中的情况不同的是,如果出现这三种问题,通过查看 CPU 和系统内存情况是无法排查出问题原因的,因为它们只是局部的阻塞,CPU 和系统内存使用率都不高,所以需要用一些其他的手段来排查。
3.1 代码中有阻塞性的操作
代码阻塞使用不当,会导致调用相关功能时比较耗时。比较典型的例子是,访问某个接口经常需要 2~3s 才能返回,而且是不定时出现。
定位这种问题的思路如下:首先找到该接口,通过压测工具不断加大访问力度,如果该接口中有某个位置比较耗时,由于访问的频率非常高,那么大多数的线程最终都将阻塞于该阻塞点,这样通过多个线程的堆栈日志,就可以定位到接口中耗时的代码位置。
3.2 某个线程进入 WAITING 状态
如果某个线程进入 WAITING 状态,可能接着导致主线程也进入 WAITING 状态,这是比较少见的一种情况,且具有一定的不可复现性,在排查的时候是非常难以发现的。在 jstack 日志中,即使是在正常的情况下,也会有很多线程处于 TIMED_WAITING 状态,这与出现 WAITING 问题的线程状态一模一样,非常容易混淆我们的判断。
定位这种问题的思路如下:通过 grep 在 jstack 日志中找出所有处于 TIMED_WAITING 状态的线程,将其导出到某个文件中,如 log1.log,等待几分钟之后,再次对 jstack 日志进行 grep,将其导出到另一个文件,如 log2.log。重复上述操作,待导出 4、5 个文件之后,再对导出的文件进行对比,找出在这几个文件中一直都存在着的用户线程,基本上就能确定是哪里出问题了, 因为正常的请求线程是不会在 30s 之后还是处于等待状态的。
如果找到了多个,那么要排除掉框架自带的线程,找包含了用户自定义的线程名或者类的线程,再查看其堆栈信息即可。
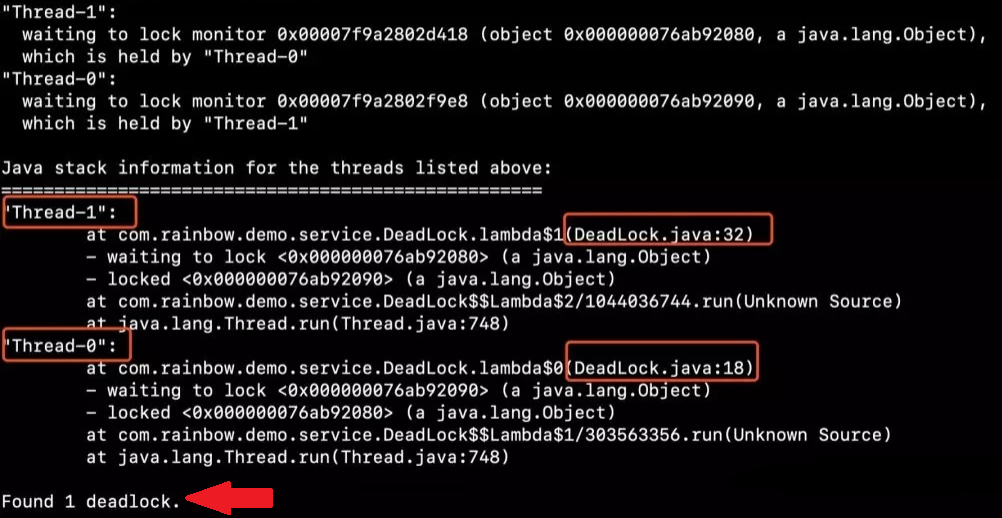
3.3 死锁
如果锁使用不当,就有可能造成死锁。定位死锁的思路很简单,直接用 jstack 命令即可:
1 | 检查死锁:jstack <pid> |
它自带检查死锁的功能,会在日志底部打印出代码中存在哪些死锁,以及每个死锁的线程堆栈信息,我们可以根据这些很容易定位到发生死锁的代码位置。
(完)