
本篇文章主要介绍垃圾收集算法,但是由于各个平台的虚拟机实现方法各不相同,因此这里只介绍几种常见算法的思想。(以堆内存的回收为例讲解这几个算法)
顺带提一下,判断一个对象是否应该被回收,用的是可达性分析法,即凡是从 GC roots 出发所能引用到的对象都不能回收。那么哪些对象可以作为 GC roots 呢?GC 管理的主要区域是 Java 堆,所以可以选择方法区、栈和本地方法栈内的对象作为 GC roots。大致包括这几类:
- 虚拟机栈(栈帧中的局部变量表)中引用的对象;
- 方法区中的类静态属性引用的对象;
- 方法区中的常量引用的对象;
- 本地方法栈中 JNI 引用的对象。
下面正式开始介绍垃圾收集算法:
1 标记-清除算法
最基础的收集算法,后续的收集算法都是基于这种思路并对其不足进行改进后才得到的。
实现思想:
从名字就可以看出,此算法分为「标记」和「清除」两个阶段:首先标记出所有需要回收的对象,然后在完成后统一回收已标记的对象。
不足之处:
1.1 标记和清除两个过程的效率都不高;
1.2 清除之后会产生大量不连续的内存碎片。空间碎片太多可能会导致程序在运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2 复制算法
适用于:
解决标记-清除算法的效率问题,适用于堆的新生代区域的回收。
(一般会将堆内存分为新生代和老年代。不分代其实也可以,分代的唯一理由就是优化 GC 性能。可以想象如果没有分代,那我们所有的对象都在一块,GC 的时候会为了去找到哪些对象没用而对堆的所有区域进行扫描,但事实上很多对象都是朝生夕死的,每次都全局扫描的话效率非常低。有了分代以后我们就能根据每个年代的特点针对性的回收。)
实现思想:
将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次性清理掉。
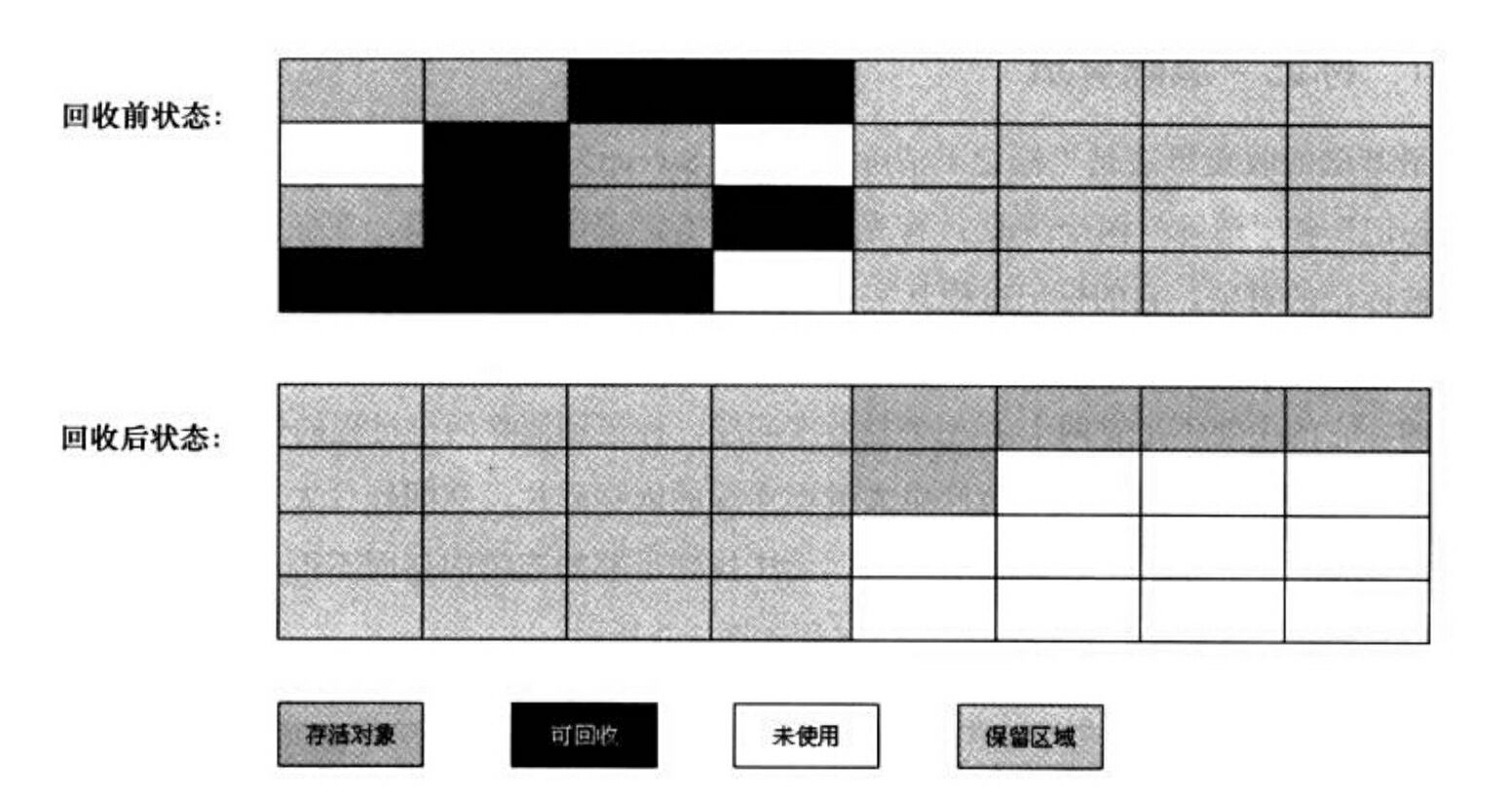
优点:
由于每次都是对整个半区进行内存回收,因此分配时就不用考虑内存碎片等情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。
缺点:
将内存缩小为了原来的一半,代价太高了一点。
扩展:
现在的商业虚拟机都采用这种收集算法来回收新生代,IBM 公司有研究表明,新生代中的对象有 98% 都是「朝生夕死」的,所以并不需要按照 1:1 的比例来划分内存空间。
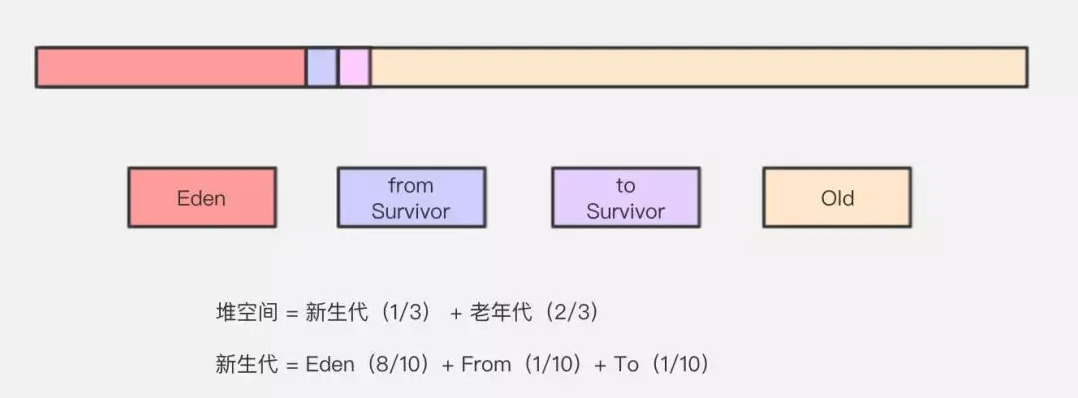
一般会把新生代分为一块较大的 Eden(伊甸园)空间和两块较小的 Survivor 空间,每次使用 Eden 和其中一块 Survivor 。当回收时,将 Eden 和 Survivor 中还存活着的对象一次性地复制到另外一块 Survivor 空间上,最后清理掉 Eden 和刚才用过的 Survivor 空间。
Sun HotSpot 虚拟机默认 Eden 和 Survivor 的大小比例是 8:1,也就是每次新生代中可用内存空间为整个新生代容量的 90%,只有 10% 的内存会被「浪费」。当然,98% 只是一般场景下的数据,我们没有办法保证每次回收都只有不多于 10% 的对象存活,当 Survivor 空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion)。
内存的分配担保就好比我们去银行借款,如果我们信誉很好,在 98% 的情况下都能按时偿还,于是银行可能会默认我们下一次也会按时按量偿还,只需要有一个担保人能保证如果我不能还款时,可以从他的账户扣钱,那银行就认为没有风险了。
内存的分配担保也一样,如果另外一块 Survivor 空间没有足够空间存放上一次新生代收集下来的存活对象时,这些对象将直接通过分配担保机制进入老年代。
附上一张图来帮助理解:
3 标记-整理算法
适用于:
解决复制算法在对象存活率较高时的效率低下问题,并且复制算法也需要额外足够的空间来做分配担保,以应对所有对象都 100% 存活的极端情况,所以在老年代一般不使用复制算法,而是用标记-整理算法。
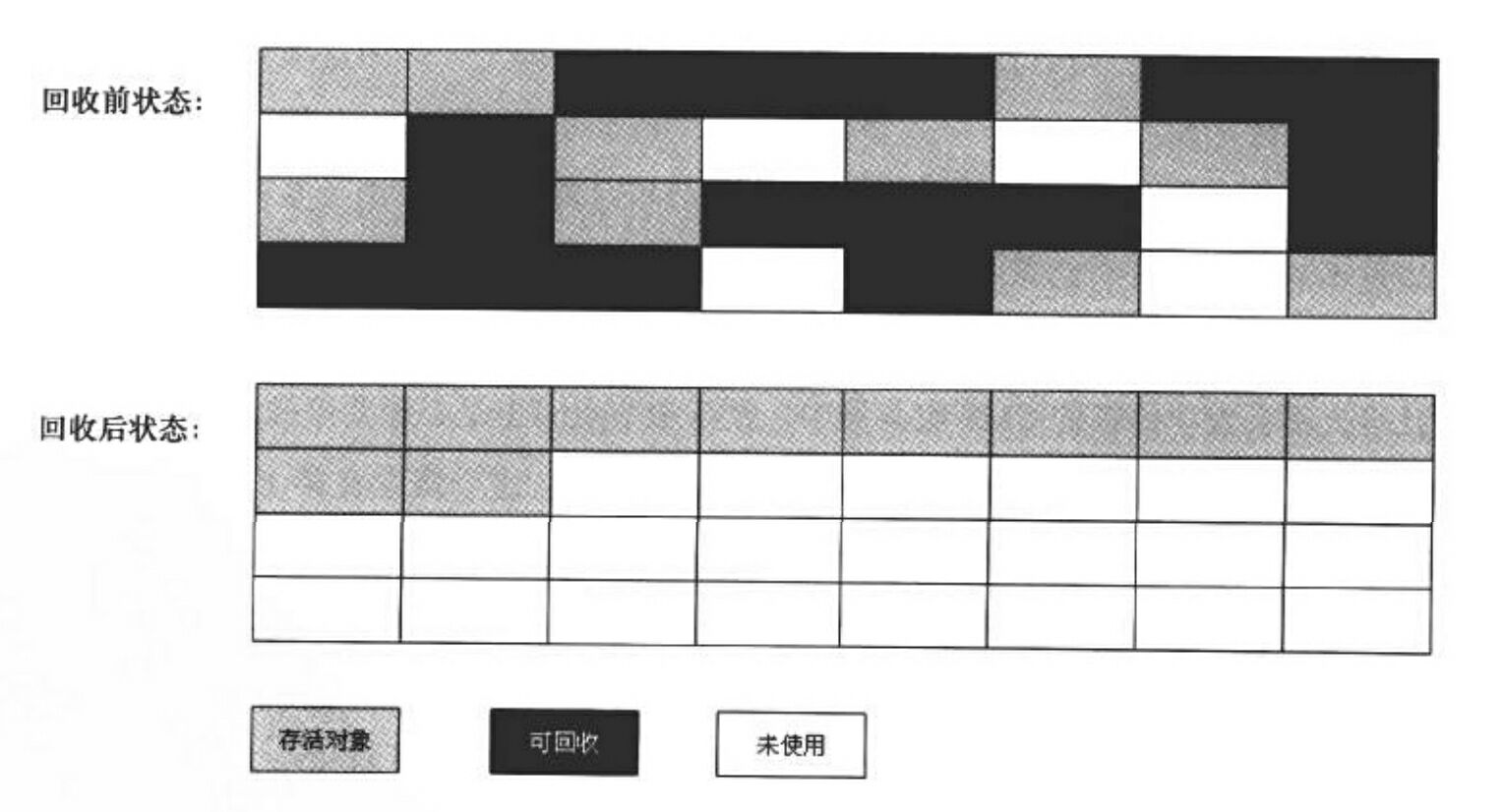
实现思想:
分为「标记」和「整理」两个阶段,标记过程仍然与标记-清除算法一样,整理过程是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
4 分代收集算法
实现思想:
根据对象存活周期的不同将内存划分为几块。在 Java 堆中,一般是将其分为新生代和老年代,然后各自采用最适当的算法进行回收。
新生代:存放新创建对象,采用复制算法。
老年代:存放长期存活对象,采用标记-清除或者标记-整理算法。
5 收集方式
5.1 串行收集
使用单线程处理垃圾回收工作,实现容易,效率较高。
不足之处:需要暂停用户线程,且无法发挥多处理器的优势。
5.2 并行收集
使用多线程处理垃圾回收工作,速度快,效率高。理论上 CPU 数目越多,越能体现出并行收集器的优势。
不足之处:仍然需要暂停用户线程。
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行,多个线程互不抢占 CPU 资源,可以同时进行,通常涉及到多个处理器。所以无论从微观还是从宏观来看,二者都是一起执行的。目的是充分利用硬件资源来加速任务的执行,提升吞吐量,更适用于处理计算密集型任务,对响应时间要求不高,例如图像处理、科学计算、视频编码等。

5.3 并发收集
垃圾回收线程和用户线程同时工作,系统在垃圾回收时不需要暂停用户线程。
并发(concurrency):指在同一时刻,只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把 CPU 运行时间分成若干段,使多个进程快速交替的执行。在同一个 CPU 下,因为切换得很快,所以使用户认为操作系统一直在服务于自己的程序,是一种 OS 欺骗用户的现象。目的是提高系统的效率和响应性,更适用于处理 I/O 密集型任务,例如网络通信、文件操作、用户界面等。
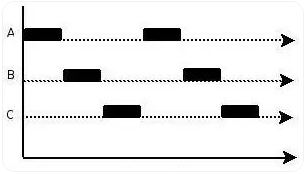
实际上,当程序中写下多进程或多线程代码时,这就意味着是并发而不是并行。因为并行与否是由操作系统的调度器决定的,和 CPU 核心数也没有关系,程序员无法控制,调度算法可能会让多个进程/线程被调度到同一个 CPU 核心上。所以在实际使用中几乎总是会存在并行,但却不能 100% 的保证都是在并行,并发并行都有可能。
5.4 生活举例
串行:家里一个灶,必须先烧完水,然后才开始炒菜(所有事按一定顺序,做完当前的事情后才能做下一件事);
并行:一个灶不够用,再加一个灶,一个灶烧水的同时,另一个灶炒菜(同一时间做(doing)多件事情的能力);
并发:家里一个灶,烧一会水炒一会菜,再烧会水再炒会菜(同一时间应对(dealing with)多件事情的能力)。
注意: 如果是单进程/单线程的并行,那么效率还不如串行。
6 认识垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。不同厂商、不同版本的虚拟机所提供的垃圾收集器都可能会有很大差别,此处选择 Sun HotSpot 虚拟机进行说明(Sun HotSpot 虚拟机是目前使用最多的 Java 虚拟机)。
下图展示了作用于不同分代的收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用。收集器所在的区域,则表示它是属于新生代收集器还是老年代收集器。另外要清楚的一点是,没有万能的完美收集器存在,而只有在某个场景下最合适的收集器。
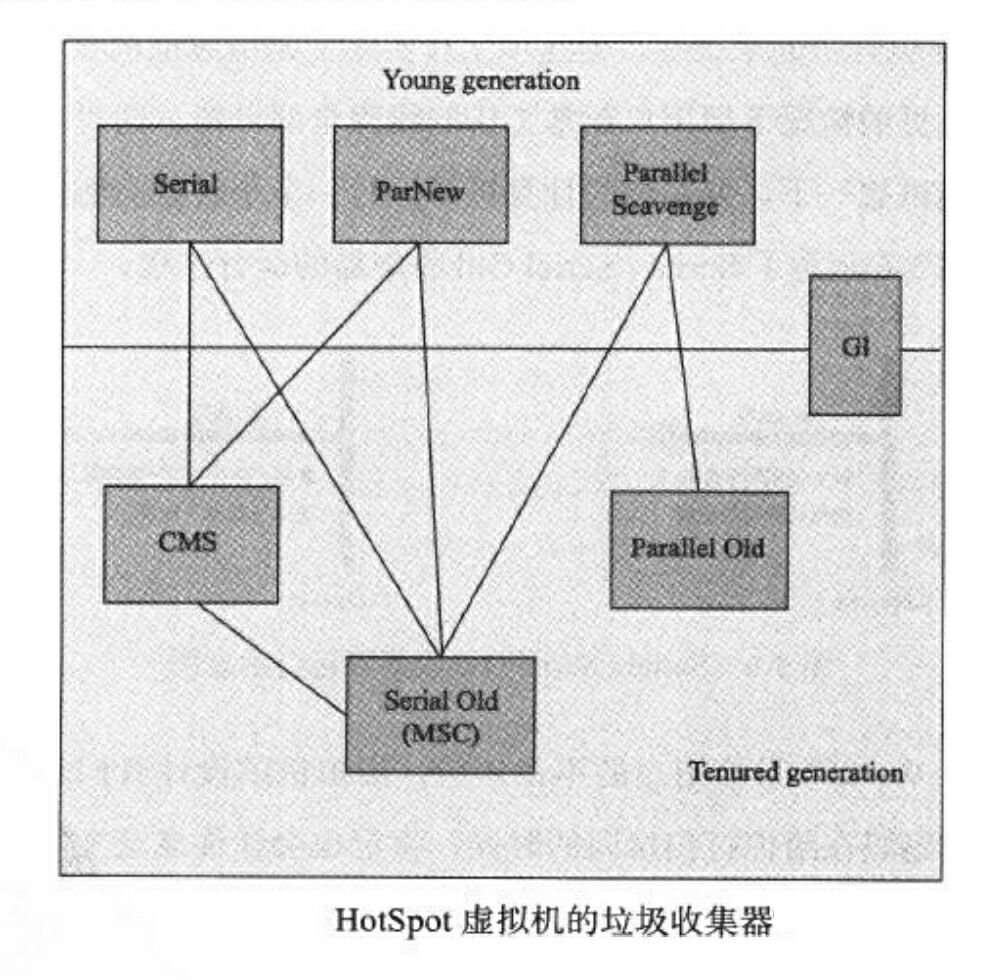
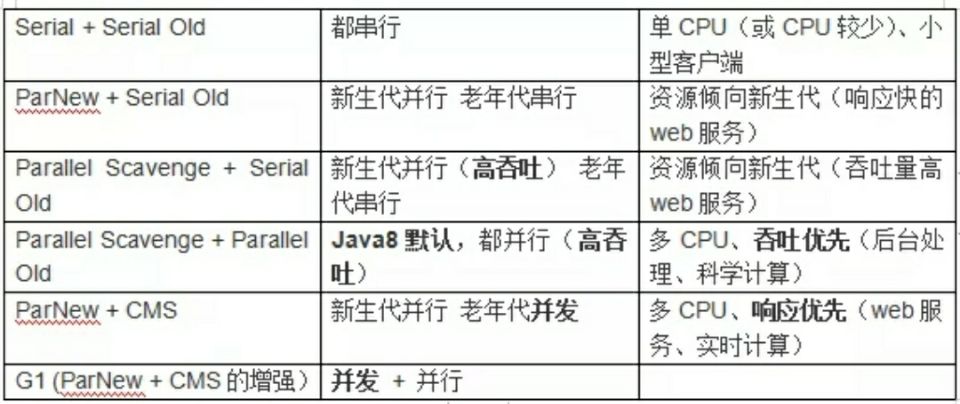
最新的垃圾收集器还有 ZGC 和 Shenandoah,特点为不区分新生代和老年代,全堆范围内统一并发回收,实现低延迟。
JVM 调优点:
6.1 内存管理优化
- 堆内存配置:设置初始堆(-Xms)和最大堆(-Xmx)为相同值,避免动态扩容带来的开销;
- 元空间配置:设置元空间初始大小(-XX:MetaspaceSize)和上限(-XX:MaxMetaspaceSize),避免频繁扩容;
- 线程栈大小:根据线程数调整线程栈大小(-Xss1m),避免栈溢出;
- 直接内存配置:针对 NIO 操作,配置直接内存上限(-XX:MaxDirectMemorySize),防止 OutOfMemoryError。
6.2 垃圾回收优化:
- 选择合适的垃圾回收器:高吞吐场景使用 Parallel GC,低延迟场景选用 G1 GC(-XX:+UseG1GC);
- 调整 GC 参数:控制 GC 最大停顿时间(-XX:MaxGCPauseMillis=200ms),控制对象晋升阈值(-XX:MaxTenuringThreshold=8,控制对象在新生代中经历多少次 Minor GC 后晋升到老年代,默认为 15,CMS/G1 下为 6),编写代码时也要注意避免频繁创建大对象。
6.3 使用监控与分析工具
- 性能监控:使用 JVisualVM、JConsole 实时监控堆内存、GC 频率及线程状态,并开启 GC 日志;
- 堆转储分析:通过 jmap 生成堆转储快照文件,用 MAT 工具定位内存泄漏;
- 命令行工具:通过 jstat -gc 查看各代容量与 GC 次数。
6.4 调优原则
- 渐进式调整:每次仅修改 1-2 个参数,通过压测验证效果;
- 场景适配:根据应用类型(高并发、大数据处理等)选择针对性策略(如高并发场景优先优化 GC 停顿)。
7 一个对象的一辈子
我是一个普通的 Java 对象,出生在 Eden 区,在 Eden 区我看到和我长得很像的小兄弟,和他玩了挺长时间。
有一天 Eden 区中的人实在是太多了,我就被迫去了 Survivor 区的「From」区,自从去了 Survivor 区,我就开始漂泊了,有时候在 Survivor 的「From」区,有时候在 Survivor 的「To」区,居无定所。
到我 15 岁时(每 GC 一次加一岁),我去了老年代那边,那里的人年龄都挺大的,我也交了很多朋友,直到被回收。